After extending to arbitrary action spaces, our next step in generalizing MuZero was to work on data efficiency, and to extend it all the way to the offline RL case. We've now published this work as MuZero Unplugged at NeurIPS, below I will give a brief summary of the main ideas.
Environment interactions are often expensive or have safety considerations, while existing datasets frequently already demonstrate good behaviour. We want to learn efficiently from any such data source, without being restricted by off-policy issues or limited to the performance of the policy that generated the data: as always, we want to be able to continue improving with more training.
Reanalyse is the algorithm that allows us to do exactly this: using model based value and policy improvement operators (such as MCTS in MuZero), we can generate new training targets for any data point, whether it was obtained from our own past environment interaction, or stems from some external datasets. Importantly, the improvement depends on the quality of the neural network used in this improvement step, so as we obtain better network checkpoints we can repeatedly generate new targets for the same datapoint.
We can then use Reanalyse for a variety of different purposes:
- Data Efficiency, by reanalysing the most recent N environment interactions and training on a mix of environment interactions and reanlaysed data. The ratio between fresh and reanalysed data is the reanalyse fraction.
- Offline RL, reanalyse existing datasets without any environment interactions (reanalyse fraction = 100%).
- Learning from Demonstrations, for example from human experts. We use reanalyse to quickly bootstrap learning in difficult environments, while still being able to learn to ignore the demonstration policy later during training.
- Exploitation, instead of using the most recent, we keep the N "best" (e.g. highest reward) states to reanalyse. Useful to quickly learn from rare events in hard exploration problems. Care must be taken in stochastic environments where some episodes are much easier than others.
For data efficiency, varying the Reanalyse fraction allows us to learn efficiently for almost any frame budget:
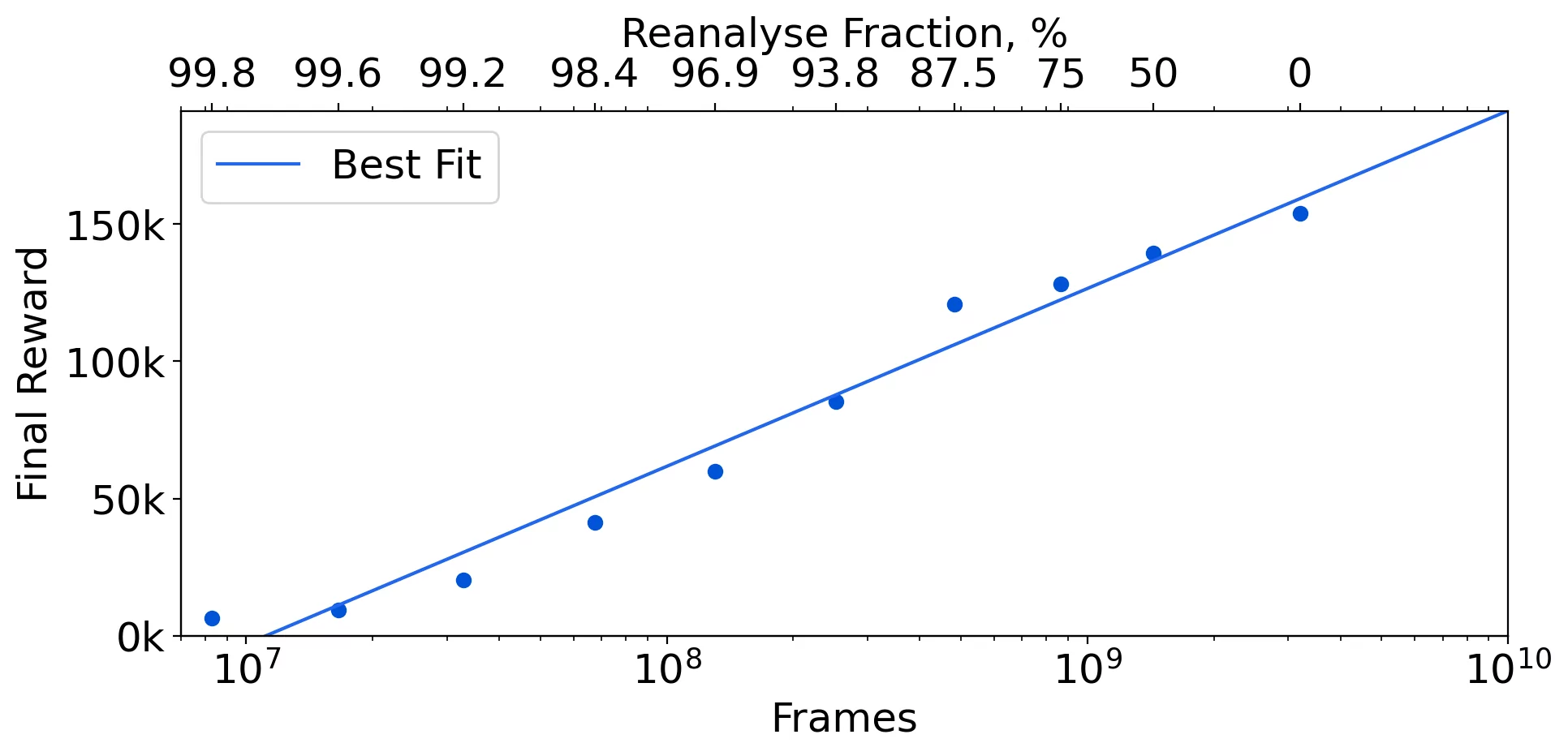
The log-linear relationship between amount of data and final performance shows interesting similarities to scaling laws observed for transformer based language models.
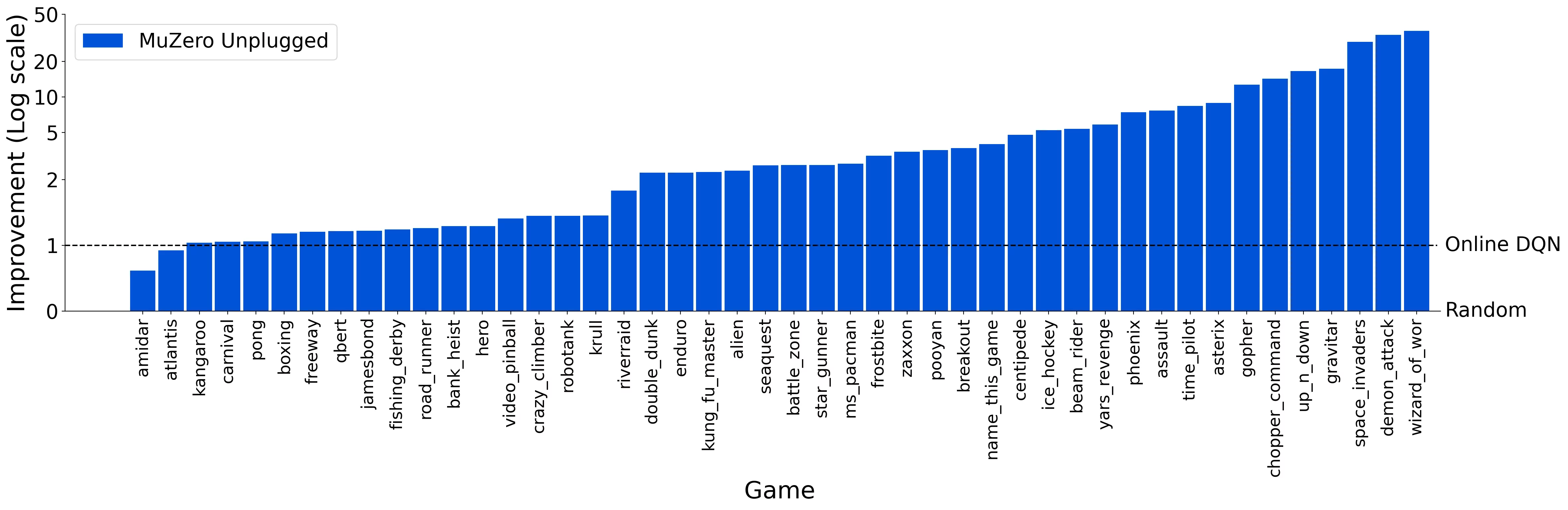
Because the policy improvement step is based on the distribution of MuZero's MCTS (not on the actions in the original trajectory), the performance of MuZero Unplugged can also exceed the performance of the policy that generated the original dataset by large margins:
There are three main contributions to the performance of MuZero Unplugged:
- Use of an n-step unrolled learned model improves the performance of the learned value estimates (0 vs 5 unroll steps)
- Use of MCTS for action selection (MCTS row vs policy/value row)
- Use of MCTS as a training target (Reanalyse column)
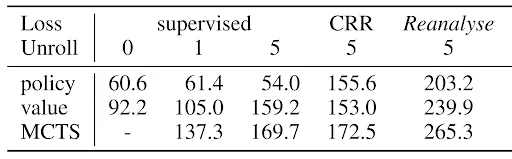
Note: The n-step model is also beneficial as a purely auxiliary loss, even when otherwise not using planning at all (see first columns of 'value' row). We recommend its use for all value based algorithms [1].
For more details, see our paper, our poster and our spotlight talk at NeurIPS (YouTube version of the talk).