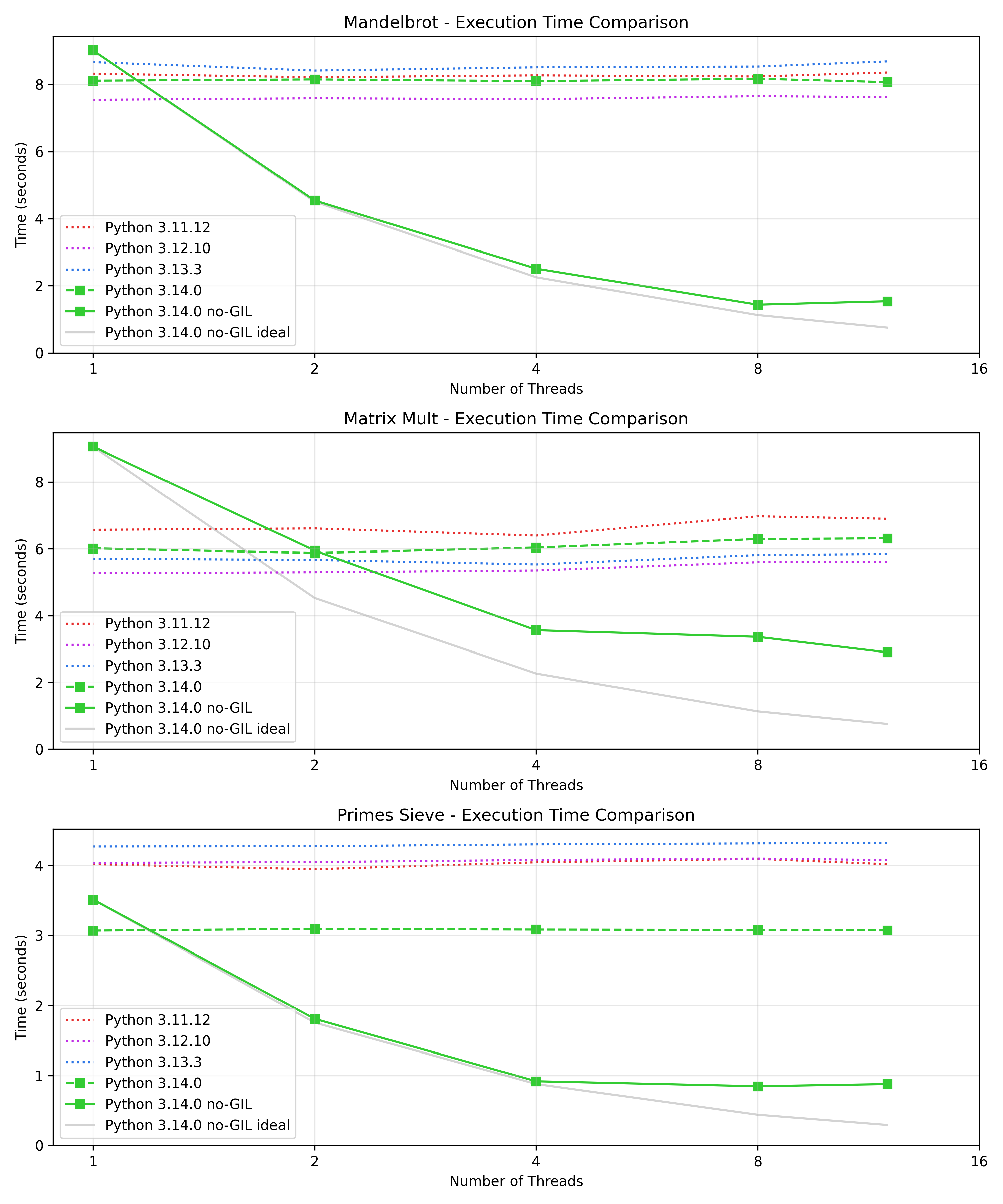
I mentioned in my previous post a lock contention issue when accessing the same list from different threads, leading to worse performance the more threads were used. Turns out this is fixed in Python 3.14.0a7 already!
Unfortunately this version doesn't (yet) seem available from uv (which is why I hadn't originally tried it), but it can be downloaded and installed manually from the Python website (click Customize at the installation step and check the free-threading box). On Mac OS, the interpreter binaries can then be found at:
/Library/Frameworks/Python.framework/Versions/3.14/bin/python3/Library/Frameworks/PythonT.framework/Versions/3.14/bin/python3t
With this version we observe much more reasonable scaling out of the box across all three benchmarks:
Transpose
During all this benchmarking I couldn't help but notice that the matrix multiplication is quite naive, in more realistic code we would at the very least transpose B before multiplying. This gets us sequential memory access in the inner loop:
def matrix_multiply_row(args):
"""Multiply one row of matrix A with B (for threading)"""
i, A, B_transpose = args
n = len(B_transpose)
row = [0] * n
for j in range(n):
A_row = A[i]
B_row = B_transpose[j]
sum = 0
for k in range(n):
sum += A_row[k] * B_row[k]
row[j] = sum
return i, row
def matrix_multiply(A, B, num_threads=1):
"""Multiply two matrices using specified number of threads"""
n = len(A)
C = [[0 for _ in range(n)] for _ in range(n)]
B_transpose = [[0 for _ in range(n)] for _ in range(n)]
for i in range(n):
for j in range(n):
B_transpose[j][i] = B[i][j]
# Prepare row tasks
tasks = [(i, A, B_transpose) for i in range(n)]
# Execute with ThreadPoolExecutor - works for both sequential and parallel
with ThreadPoolExecutor(max_workers=num_threads) as executor:
for i, row in executor.map(matrix_multiply_row, tasks):
C[i] = row
return C
Aside:
sum = 0
for k in range(n):
sum += A_row[k] * B_row[k]
row[j] = sum
might seem like a tempting place to use sum and zip:
row[j] = sum(a * b for a, b in zip(A_row, B_row))
but this is actually much slower, probably because zip has to create temporary tuple instances.
Overall the transpose trick gives us a roughly 2x speed-up, and somewhat better scaling behaviour:
![]()
Concurrent Reads
While investigating this issue I started benchmarking concurrent reads on various data structures. The good news is that in alpha 7, most containers (list, tuple, dict, string, bytes) can now be quickly read from multiple threads, only bytearray remains slow.
If you are curious, there's a gist with full benchmark and results.
Tags: python, programming, threading