From Musk's "Potentially more dangerous than nukes." tweet, increased funding for the Machine Intelligence Research Institute (MIRI) to the founding of cross-industry groups like the Partnership on AI, AI is being taken more seriously.
One worry that is sometimes cited, as in the book Superintelligence by Nick Bostrom, is that once we reach human-level AI, it might rapidly improve itself past anything humans can envision, becoming impossible to control. This is called "Singularity", because anything after such a point is unforseeable.
The argument for a Singularity rests on the fact that a hypothetical AI could devote all its resources to improving itself, use its new found abilities to improve itself even faster, and thus increase its capabilities exponentially:
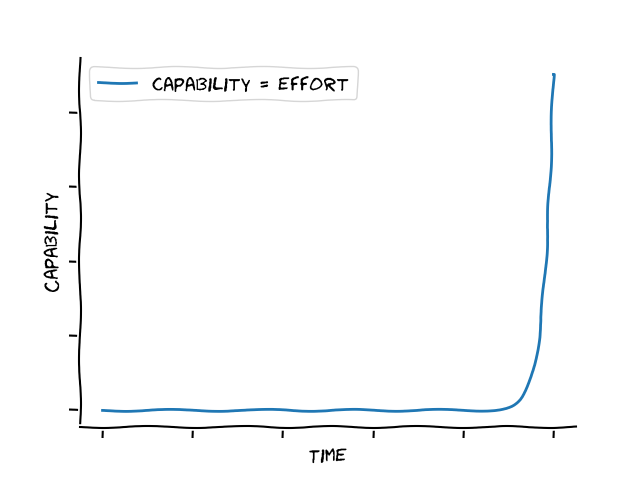
But how likely is such a scenario?
With nearly 8 years since AlexNet and more than 5 since DQN, we can examine the track record of deep learning to give us some intuition.
In deep reinforcement learning, Atari has long been the domain of choice for many researchers, attracting fierce competition to obtain the best score. (Reinforcement learning concerns itself with how agents should interact with their environment to maximise some measure of reward.)
If we plot the scores obtained in various top papers against the number of environment interactions of the agent - a rough measure of training effort - we obtain the following plot:
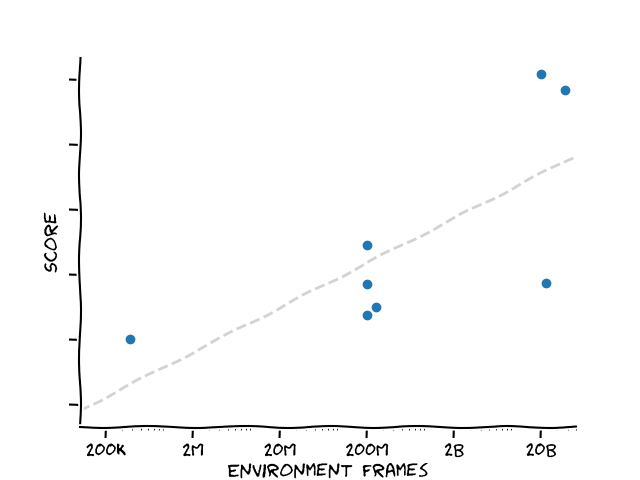
More effort does indeed lead to better performance, but note that the x-axis is logarithmic! To obtain constant improvements in score, an agent needs to expend exponentially more effort.
Similar relationships hold in other domains. Let's take one I'm most familiar with, the playing strength of AlphaGo Zero, measured in Elo, over the course of 40 days of training (as reported in the AlphaGo Zero paper):
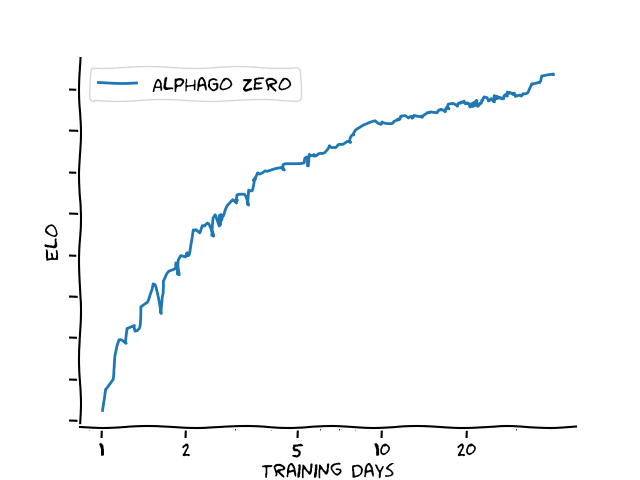
Again, increased training leads to better performance, and again note the logarithmic x-axis - except in this case, the return on training effort seems even worse.
Using what we learned from these domains - \text{capability} = log(\text{effort}) - and applying it to our original AI self-improvement graph, we end up with:
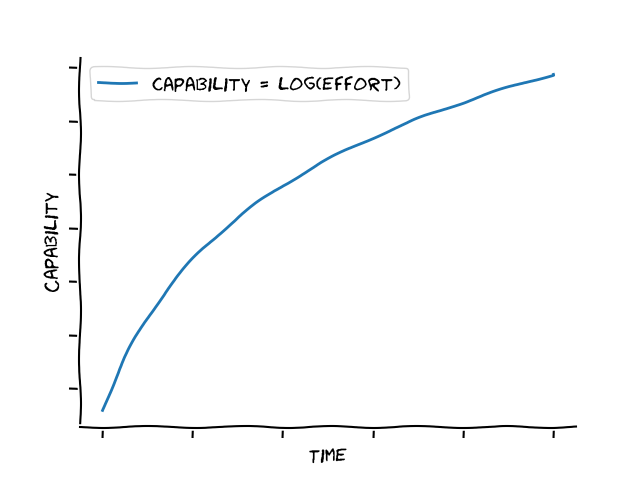
Far from an explosion of ability, improvement seems to peter out and become slower and slower.
In fact, this phenomenon is not constrained to machine learning or AI - similar results seem to hold for other fields of research. In Are Ideas Getting Harder to Find? Bloom et al provide convincing evidence that while the number of researchers has been growing for decades, research productivity and output has actually been declining!
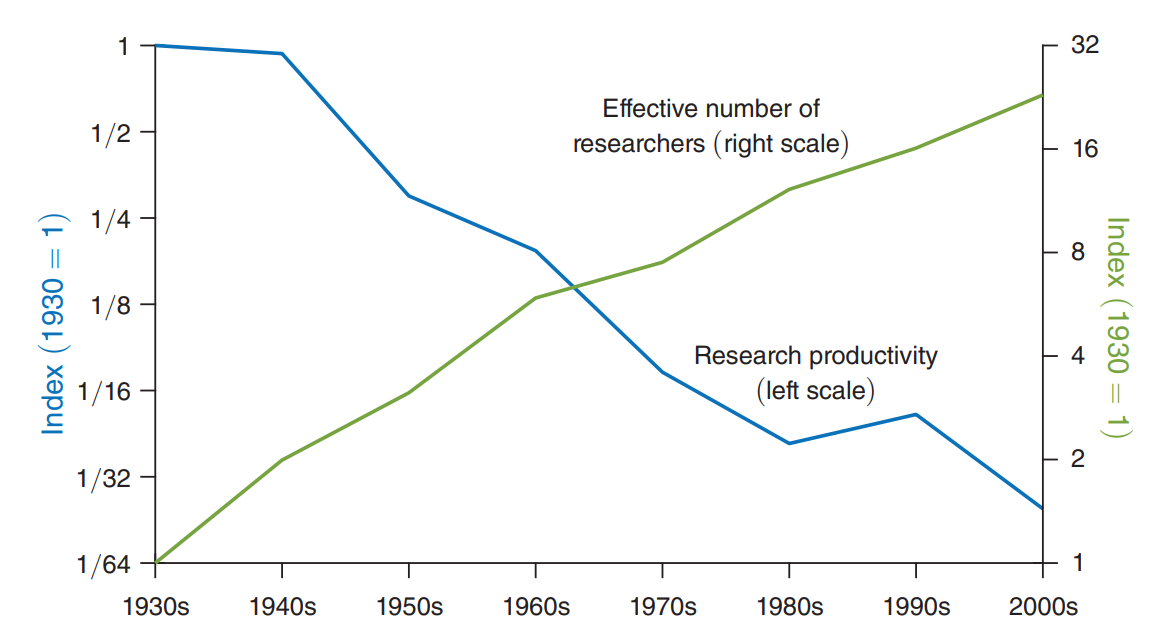
Figure 2 from Are Ideas Getting Harder to Find?, consistent with decreasing return on effort.
Not only is there no free lunch, lunch gets more expensive every day.
Tags: ai