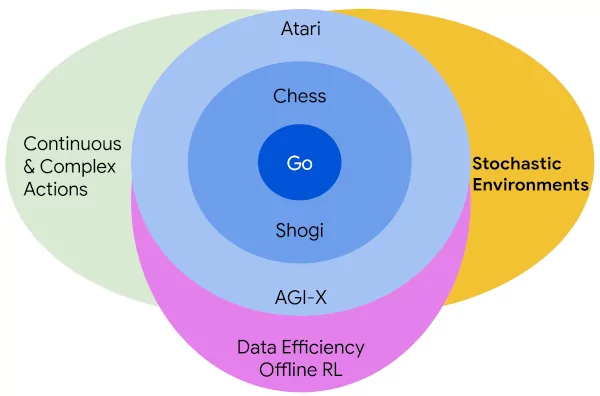
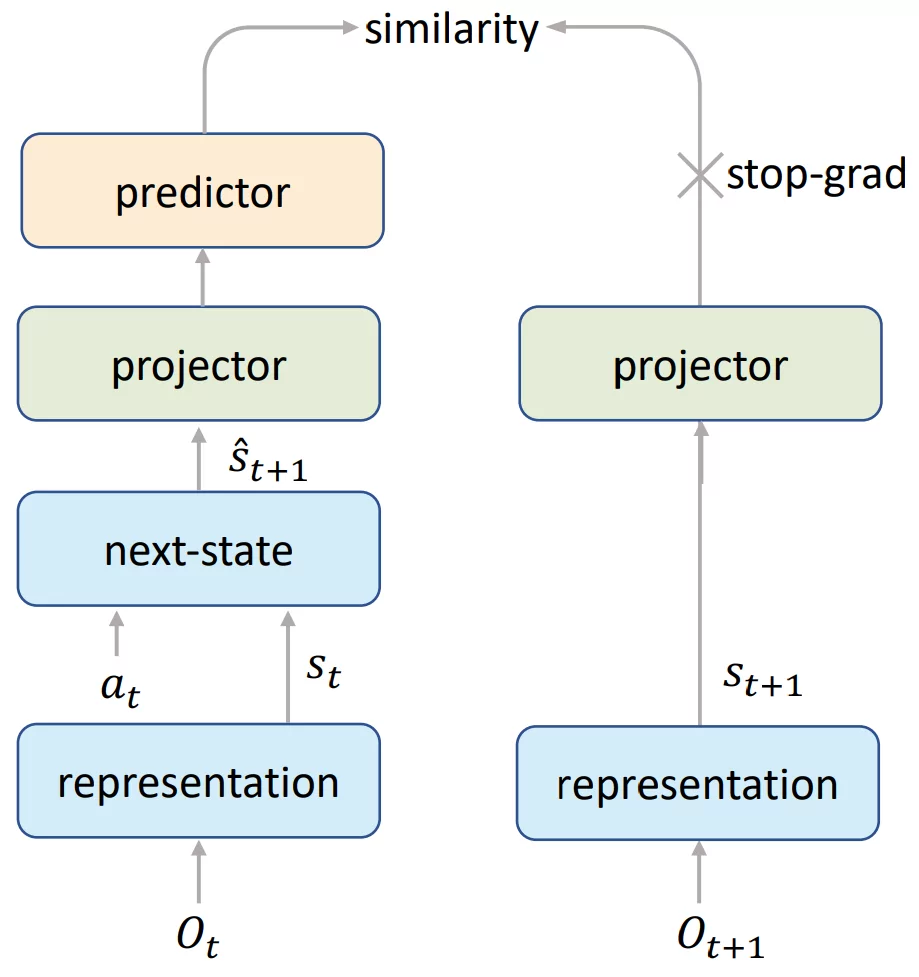
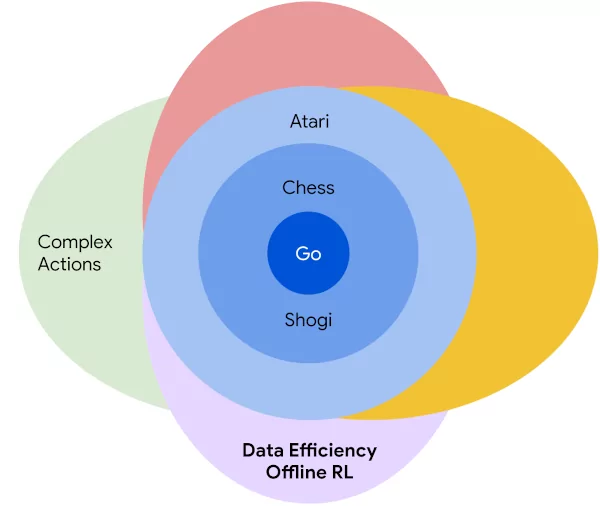
Matrix multiplication is at the foundation of modern machine learning - whether transformers or convolutional networks, diffusion models or GANs, they all boil down to matrix multiplications, executed efficiently on GPUs and TPUs. So far the best known algorithms have been discovered manually by humans, often optimized for specific use cases.
The most famous is probably the [cached]Strassen algorithm to multiply two 2x2 matrices using only 7 instead of the naive 8 multiplications:
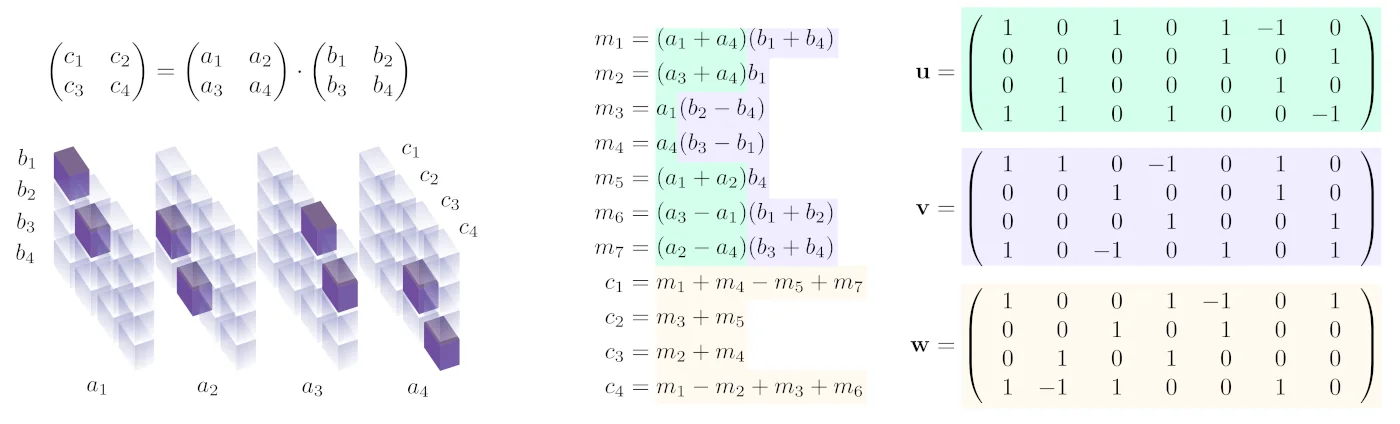
Through clever addition and subtraction of the individual elements of the a and b matrices this algorithm is able to combine the intermediate results into the elements …