Another interesting paper based on MuZero was published at NeurIPS 2021: Mastering Atari Games with Limited Data, aka EfficientZero. This paper by Weirui Ye, Shaohuai Liu, Thanard Kurutach, Pieter Abbeel and Yang Gao focuses on the application of MuZero to very low data tasks, such as Atari 100k (only two hours of gameplay!) or DMControl 100k.
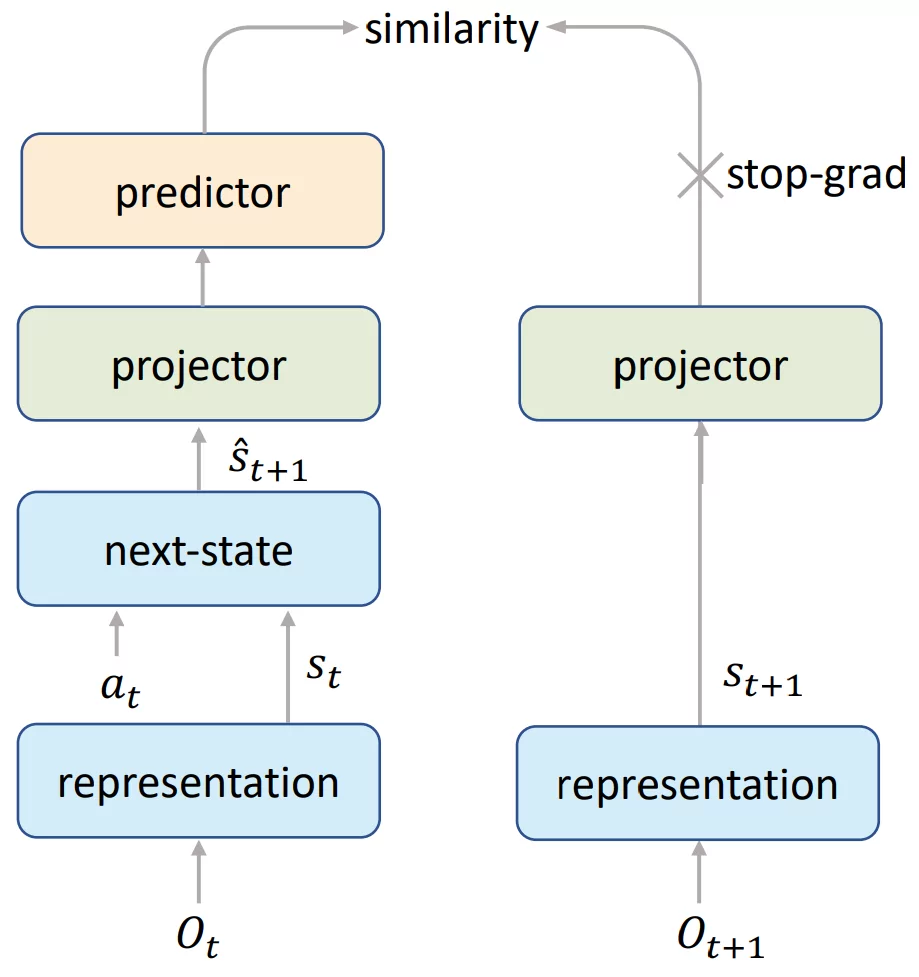
To tackle these tasks, the author propose three main techniques:
First they introduce a Self-Supervised Consistency Loss, to ensure that the embeddings produced by MuZero's dynamics function are consistent with the embeddings from the representation function. This loss is insipired by SimSiam-style representation learning. However, instead of using different augmentations of the same image, they take advantage of the fact that both the representation function for observation o_{t+1} and the representation function for o_t followed by one step of the dynamics function should lead to the same state embedding s_{t+1}.
Next they propose End-To-End Prediction of the Value Prefix, to handle the fact that sometimes it is difficult to predict in which exact frame a reward will occur. To address this, instead of predicting the reward for each individual timestep they propose to directly predict the sum of rewards since the root state in the form of a value prefix \sum_{i=0}^{k-1}{\gamma^i r_{t+i}}.
Another alternative would have been to completely merge reward and value prediction, and always predict values relative to the root state - this removes the need for any separate reward prediction [1].
Finally, they also propose Model-Based Off-Policy Correction for the value learning: re-run MCTS for the target state to obtain a new value estimate as the bootstrap target, and dynamically adjust the number of TD steps based on the age of the trajectory. Using a fresh MCTS value is the same as in MuZero Unplugged / Reanalyse, but the selection of TD steps based on trajectory age is an interesting off-policy correction alternative to VTrace[2], which could perform better in domains with many similar or aliased actions.
Overall their method works very well, achieving superhuman performance on Atari 100k (190.4% mean, 116.0% median) and strongly outperforming previous approaches. For more details, check out their paper and open-source implementation.
Personally I'm very interested to see how these techniques will perform for different data budgets (say standard Atari 200 million) and different domains. It's also exciting to see that the proposed methods are entirely complementary to MuZero Unplugged, so we should be able to combine the two approaches for even more efficient learning!
-
In my experiments value prediction relative to the root performed equivalently to normal separate value and reward prediction at the 200 million frame budget in Atari, but it's possible that the two would perform differently at low-data budgets like the Atari 100k task. ↩
-
VTrace in effect adjusts the number of TD bootstrap steps based on how likely we are to choose the actions along the trajectory under our current policy compared to the original policy, in effect truncating the bootstrap if we would choose very different actions now. ↩