In the conventional [cached]Turing test (aka imitation game), an investigator tries to distinguish between a human and a computer solely by interacting with them.
This is an interesting setup and has inspired much research, but it doesn't immediately translate into practical usefulness - a computer system may pass as human, but may still not be able to help me accomplish any task.
Instead, I find I'm mostly interested in a stricter variety: in each interaction the investigator chooses a preferred response; the goal of the computer system is to be chosen as the preferred side as many times as possible …
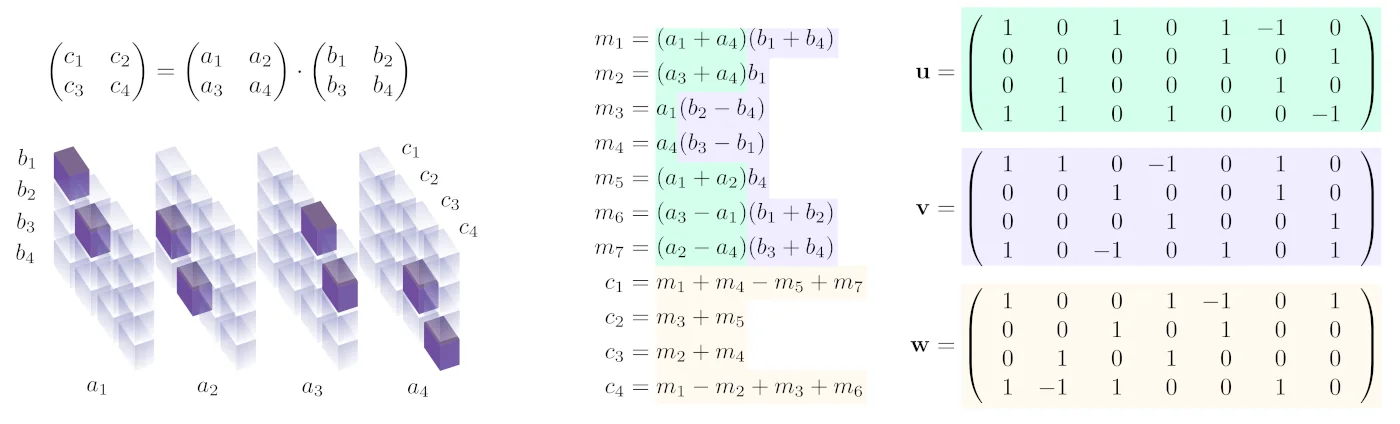
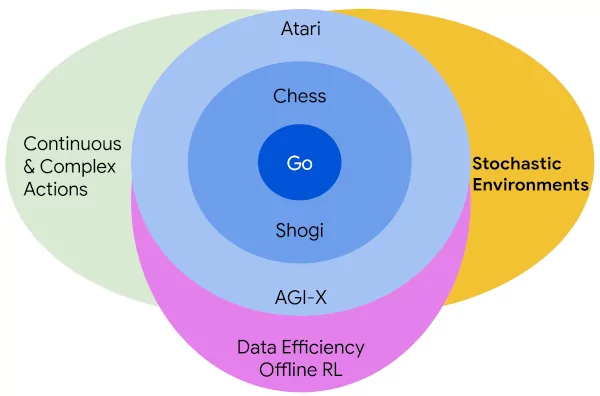
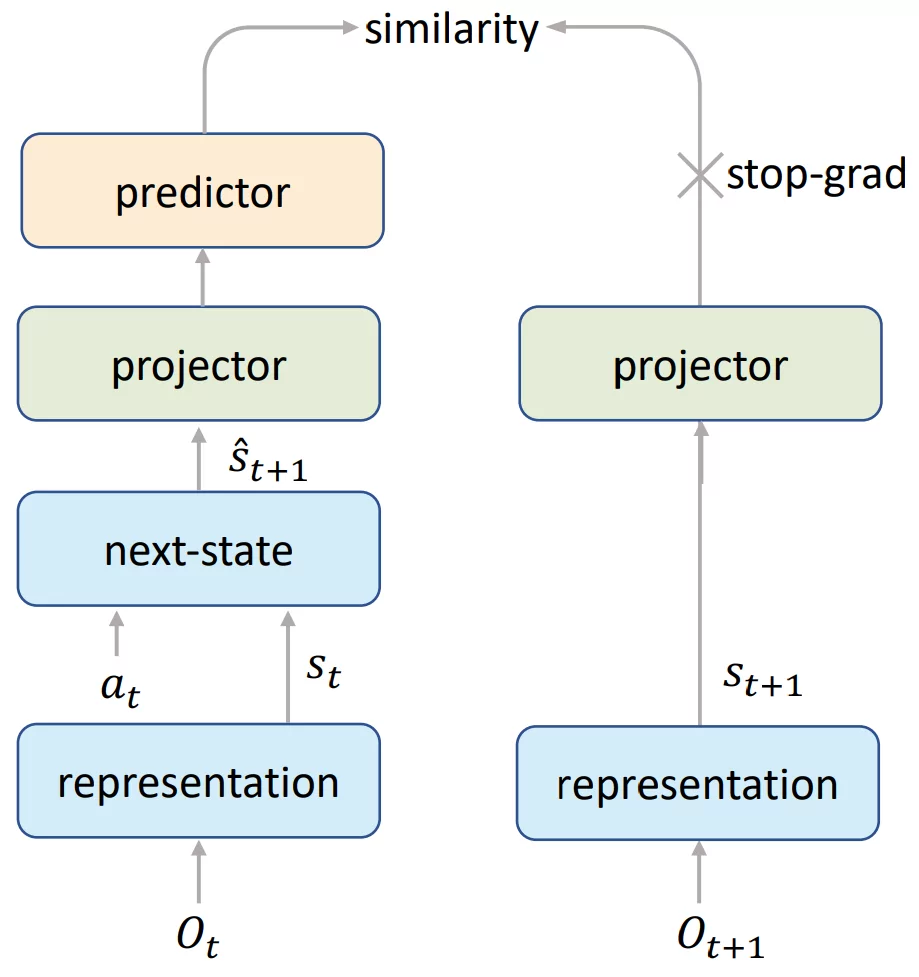
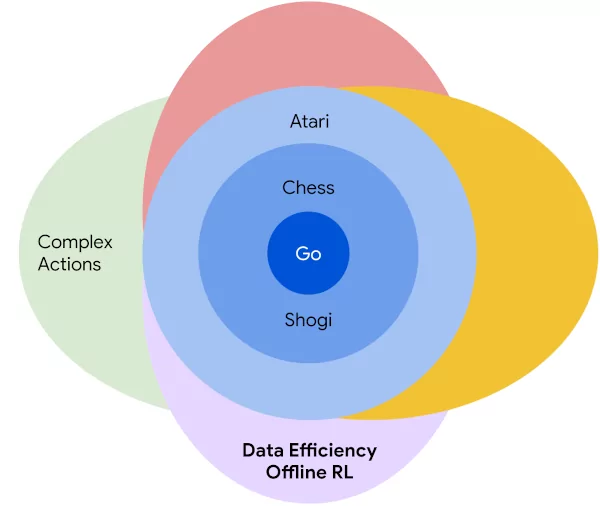
 (
(