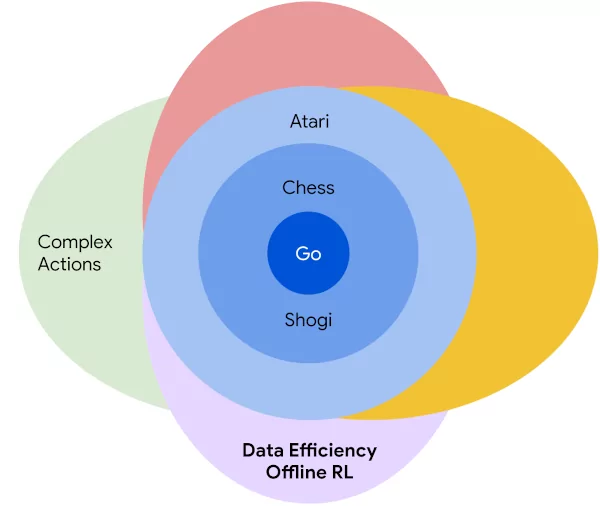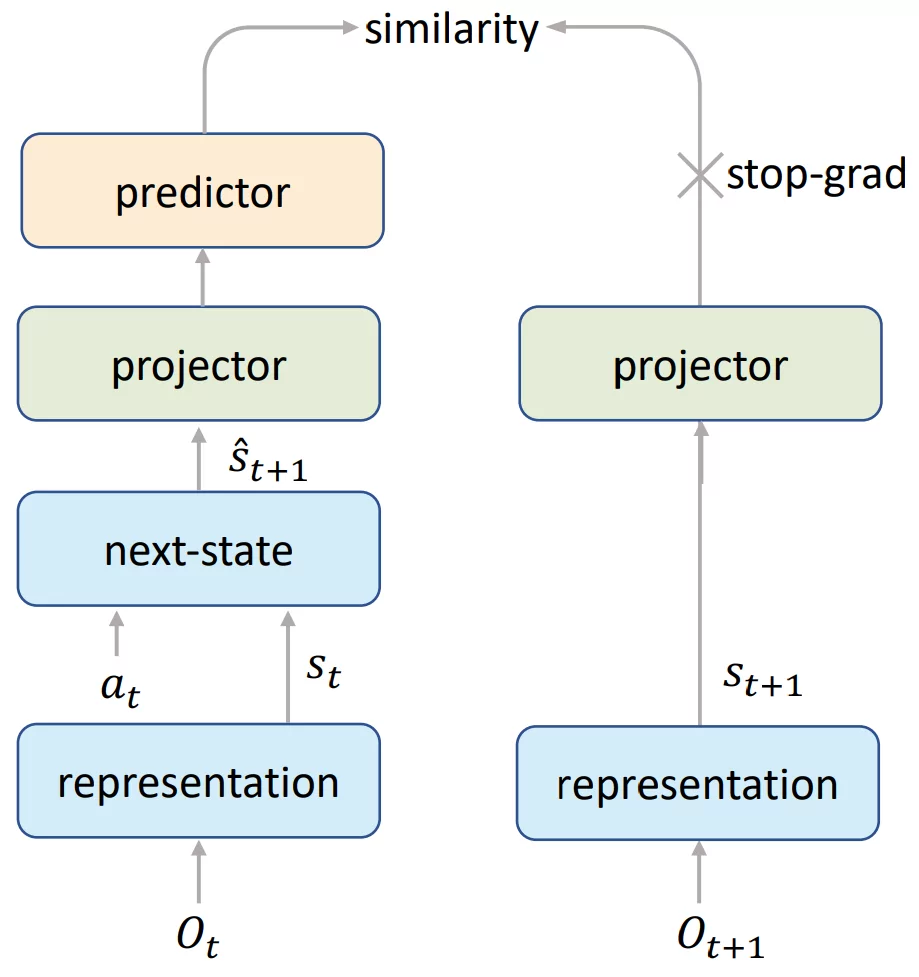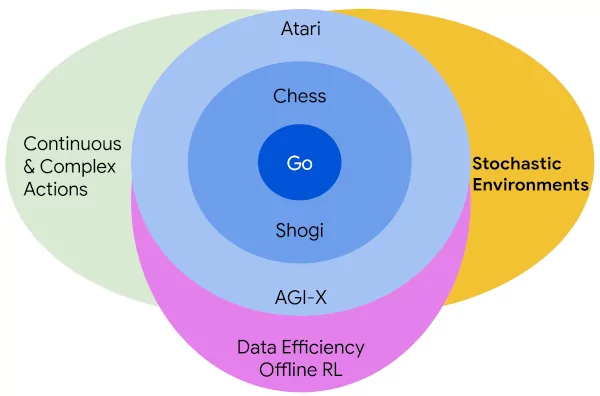
After extending to arbitrary action spaces and offline RL, we recently published our next step in generalizing MuZero: Stochastic MuZero, which learns and plans with a stochastic model of the environment that can model not only a single deterministic outcome of our actions, but rather a full set of possibilities.
Previous approaches such as AlphaZero and MuZero have achieved very good results in fully-observed deterministic environments, but this type of environment is insufficiently general to model many problems and real world tasks. Beyond the stochasticity inherent in many domains (think roll ...